
Digital HUB is an open online community of financial and data science professionals pursuing practical applications of AI in their everyday functions. Digital HUB community provides expert, curated insights into financial applications of Generative AI, Large Language Models, Machine Learning, Data Science, Crypto Assets and Blockchain.
A key focus for The Digital HUB publication is to provide best practices for the safe deployment of AI at scale such as: assessing the ability to execute, determining an organization’s digital DNA, fostering skill development, and encouraging responsible AI.
Digital HUB is an open online community of financial and data science professionals pursuing practical applications of AI in their everyday functions. Digital HUB community provides expert, curated insights into financial applications of Generative AI, Large Language Models, Machine Learning, Data Science, Crypto Assets and Blockchain.
A key focus for The Digital HUB publication is to provide best practices for the safe deployment of AI at scale such as: assessing the ability to execute, determining an organization’s digital DNA, fostering skill development, and encouraging responsible AI.
Introduction
Introduction
ChatGPT and similar Large Language Models (“LLMs”) have dominated the headlines since their emergence. Clearly, generative AI has incredible potential to disrupt every industry, including portfolio management. When investment management firms consider digital transformation, there are so many aspects of the business that can benefit from this modernization; yet, adoption continues at a very slow pace. While there is significant progress in terms of technologies for CRM, client interactions, and back-office systems upgrades, the use of AI within the portfolio management process remains widely anemic.
As LLMs and other massive deep learning NLP models continue to dominate the conversations, it will eclipse the potential of smaller projects that could easily be undertaken that can improve any part of the investment process. As highlighted in my previous article, figure 1 below shows a basic flow diagram for an investment management system.
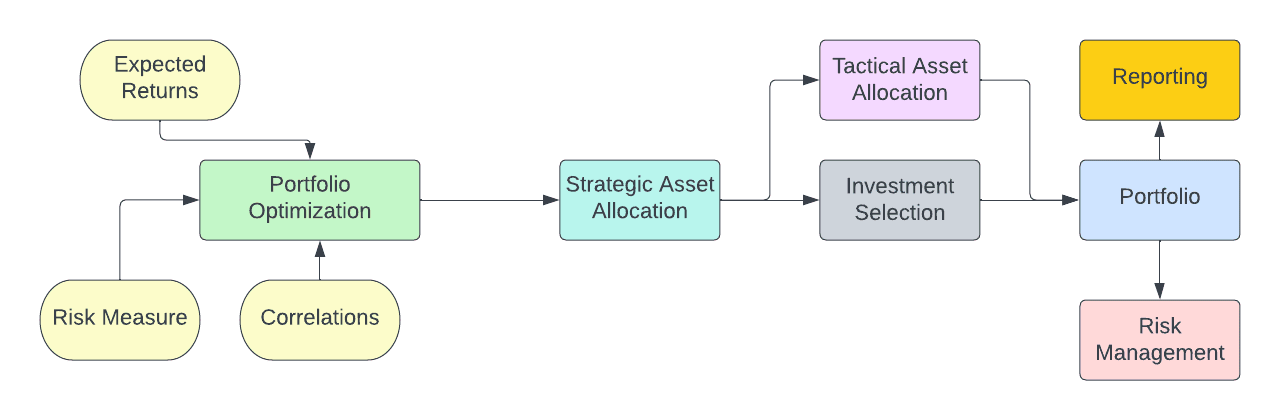
Each one of these steps can be targeted for improvement through a data science or machine learning project. And these projects need not be massive undertakings requiring hiring teams of PhD researchers in mathematics. These can be low-cost projects, and potentially quick to implement (if you build a good model, of course).
In this article, I will provide an example of how we can use machine learning to improve the tactical asset allocation process. Hopefully, readers will be challenged to build something similar that they can use in their daily routines and hopefully introduce new models to their firms that can advance digital transformation within the portfolio management process.
Tactical Asset Allocation
Imagine a fund that adjusts its holdings based on various economic and other market conditions. It is designed to adjust asset class weights based on the macro environment. This is exactly what Ray Dalio designed with the $150-billion AUM Bridgewater Associates All-Weather fund. It combines several asset classes that perform differently in diverse economic environments. The fund shifts their relative weightings according to the current state of the economy.
This is what all investors would love to do: time the market perfectly. Of course, we would all have to eventually face the issue that most investors are incredibly bad at timing the markets and we normally do more harm than good. However, can an algorithm be better at it if we remove human emotion and behavioural biases from the investment equation? Would this also not add another layer of diversification? These are all questions that would need to be proved with statistical significance.
The question then becomes: can we train a model to help us determine tactical weights for positions in our portfolio?
Selecting and Building a Model
The first step in this process would be to assess the business case, determine how we would define success, and then understand the resources needed. In this case, we want to use macroeconomic indicators, and some other indicators that we believe could be helpful (let’s say, sentiment and asset class momentum). The goal is to see if we can use these indicators to predict what our asset classes should return over the next x period (say, week or month), and then weight the asset classes accordingly.
Since we are trying to predict a future quantity, this is a regression problem, and we need to select a regression model. But which one? Linear regression? Support vector machines? Decision trees? Maybe we should try all and see which one gives us the best result. Another option would be to build an ensemble model that combines different models and takes the average prediction.
The most important aspect would be to select a model that performs well out of sample based on some evaluation metric, meaning, we need to reduce over-fitting. Using a LASSO regression or a support vector machine would be good starting points since they normally overfit less than decision trees or boosting methods.
Let’s consider the SVM approach as proposed by Joel Guglietta in the book authored by Tony Guida, Big Data and Machine Learning in Quantitative Investing
This model attempts to predict asset class returns over the next week when the algorithm is run using data at the end of every Friday. The portfolio manager would then execute the rebalancing trades at the open on the following Monday.
While the specific macroeconomic indicators used are not specified, some domain expertise would likely point us in the direction of using some first order economic indicators such as ISM surveys, employment, inflation, and retail sales. Of course, we would need to consider that many economic series have different reporting frequencies, so this would be part of our feature engineering pipeline.
We would then identify the asset classes we would like to forecast. Often, we hear that the biggest obstacle to data science projects in finance is access to data. However, given the proliferation of ETFs representing almost every conceivable liquid asset class (and sometimes illiquid), this data is readily available and often for a very low cost if not free. In this case we need historical pricing information.
Once we have identified the macro factors representing our features, we can build a training and test set based on the performance of those asset classes over the following week and use the returns as our targets. A grid search could then be employed to tune the SVM hyperparameters.
Evaluating success of the model is another matter. We would want to compare performance of the out-of-sample performance versus a buy and hold benchmark with quarterly rebalancing back to the strategic weights. Of course, using error measures will help tune the models, but ultimately, we need to demonstrate that the strategy beats the buy and hold. This where the art of building a good model is just as important as the science.
Guida, Tony; Big Data and Machine Learning in Quantitative Investment. Wiley, 2019.
Summary
The goal of this article is not to provide a working model but rather to get people thinking about low-cost, easy to implement models that can push asset managers to include data-driven methods into the portfolio management process.
I challenge all participants to break down their current workflows and attempt to build a model that can improve the portfolio management process one step at a time. If smaller working models can improve your process, organizations will hopefully begin to see that not everything requires hiring SaaS developers, data engineering teams, cloud engineers and machine learning experts. Enough resources exist for small-scale projects to have large effects. All it takes is a little inspiration, creativity, and hard work.